News
CEDA Data Catalogue - new, improved search functions!
Posted on May 3, 2018 (Last modified on October 19, 2023) • 3 min read • 442 wordsFinding the right data for your research can often be a daunting task… especially when faced with a vast archive of over 5000 datasets with 180 million files to choose from, such as in the CEDA archive! However, CEDA are pleased to announce a major step towards helping resolve this conundrum; bringing the power of industry search tools and direct metadata harvesting at scale to solve these problems.
The CEDA Catalogue now allows users to search by “variable”. This work builds upon a significant project to scan all data files (100s of millions) in the CEDA Archive and to index the resulting metadata into a single store. CEDA’s new data search allows you to search by:
- Variable long names
- Variable CF standard names
- Variable IDs (such as MIP ids)
- Record titles, abstracts, keywords and abbreviations
A free-text search now queries metadata held in titles, abstracts and keywords within the major catalogue records. It also queries the various variable names that are found in the data files. When the user visits the catalogue record, she will see a list of variables (and their associated attributes, such as “units”) available for the selected dataset.
For example, through the catalogue search you can generate a query for “ozone”. An example hit will take you here. Inside the “Variables” tab you will find a list of variables inside the data files, see Figure 1 below.
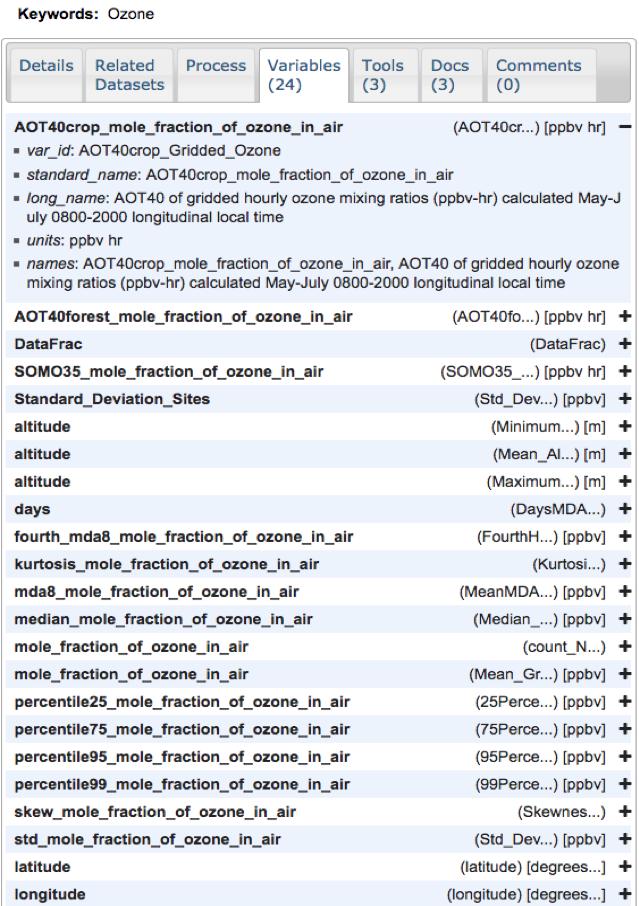
Figure 1. Example of variable tab from the ozone search result on the CEDA catalogue, as described above. The variables tab shows 24 parameters with additional information such as standard names, long names, and units.
Search results can also be filtered by the different record types in the catalogue and re-ordered based on your preference: by search relevance or in alphabetical order. In addition, variable information is available on dataset records linking long and standard names with variable IDs and units to provide a fuller picture of the data holdings.
This is part of a new, improved search tool on the CEDA Catalogue, which we’ll be developing further over the coming months to bring even more enhanced search features. This functionality is new and we encourage users to share their feedback on how it can be improved.
Using ElasticSearch technology and harvesting the power of the JASMIN system, this project provides a highly scalable indexing solution that supports a rich and flexible query model. CEDA can now easily join up our extensive data catalogue with variable details harvested directly from each file in the entire archive; resulting in enhanced catalogue search functionality and variable listings on catalogue records.
